整治費徵收金額預測AI分析系統
 2023/02/13
2023/02/13
由於整治費徵收涉及多變項因素,每季廠商申報的金額受到多重複雜變數的影響,導致費率波動幅度較大,使得預測掌握困難。因此,案主—土壤及地下水污染整治基金管理會(以下簡稱土基會)主要需求在於提升整治費徵收的「精準度」。信諾科技基於在大數據分析和機器學習領域的深厚專業和豐富的專案經驗,針對此需求開發了本專案解決方案,以滿足土基會對於高精準度徵收的要求。
緣起背景
土基會為了解決整治費徵收中的高誤差問題,期望藉由人工智慧演算法提升預測的精準度,從而應對大量而複雜的大數據需求。由於整治費的數據量龐大,每季數據皆以億為單位,且影響費率波動的變項繁多,導入大數據機器學習技術成為必要。然而,在此之前,土基會主要採用傳統迴歸分析方法(regression),但此方法在處理高維度數據上具有局限性,容易導致預測結果波動大且誤差高,無法達到所需的準確度。因此,轉向AI技術與機器學習分析,期望能有效提升整治費徵收預測的穩定性和精確度。
3分鐘掌握專案績效重點
信諾在AI演算模型的種類、數量及執行程序上具備更高的嚴謹性,不僅優於傳統方法,更進一步引入時間序列(time series)分析,有效控制因時間因素導致的預測誤差。針對不同特性的數據樣態,信諾提供相應的演算法模型,以達到最佳預測效果。
透過檢測並適配資料樣態的AI模型,信諾引入多種類的AI演算模型,並進行多種方法的排列組合測試(即多模型協作),完成繁複的運算工程。在提升計算維度與方法多元性後,信諾能有效強化案主在各種情境模擬中的選擇靈活性與精準度,使預測結果更貼近實際需求。
重要功能展示
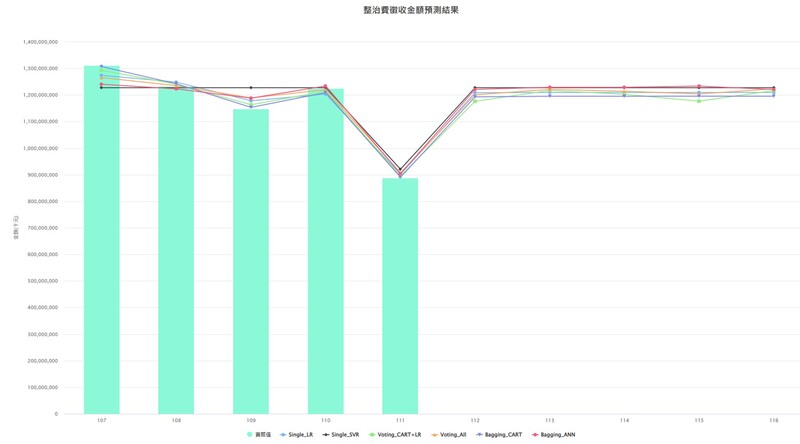 圖說:圖為系統實際使用的畫面,能針對各年份的資料進行6種預測模型的運算,在精確性上已實證比較過,確實較傳統方法優良。
圖說:圖為系統實際使用的畫面,能針對各年份的資料進行6種預測模型的運算,在精確性上已實證比較過,確實較傳統方法優良。
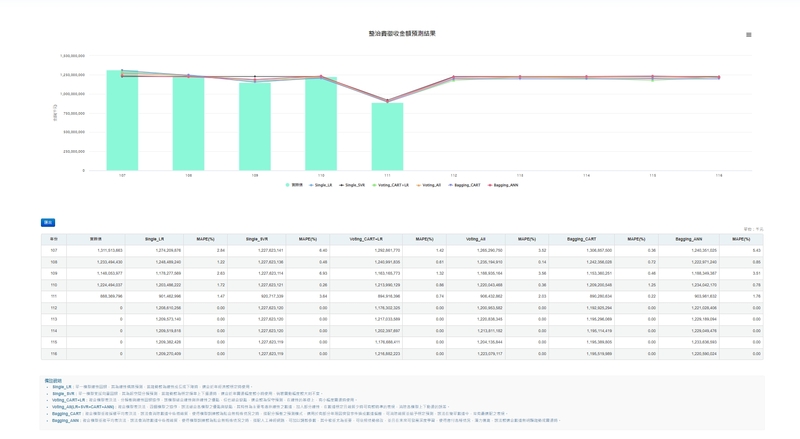 圖說:在系統的選擇性(預測模型)上,信諾提供6種模型來提供案主更多的選擇性。
圖說:在系統的選擇性(預測模型)上,信諾提供6種模型來提供案主更多的選擇性。
成果具體效益價值簡要列點如下:
- 信諾導入時間序列分析,以提高運算維度,並通過嚴謹且複雜的算法流程實現高精準度的預測,顯著降低誤差。例如,透過因子模型與時間序列模型的綜合測試,信諾能精確找出最佳模式,確保預測結果的穩定性與精度。
- 信諾擁有多樣化的工具與技術,能針對數據特性選擇最適合的模型,並結合仿生優化技術進行參數最佳化。此舉不僅提升了數據處理的適應性,還為案主提供更多元的選擇,能從不同面向滿足其預測需求。
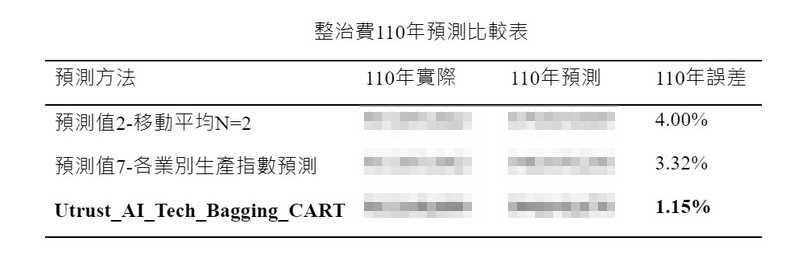 圖說:以110年的整治費預測為例,可以看出信諾在誤差值中的表現,從4.00%的誤差降到1.15%,表現的確更為優良。
圖說:以110年的整治費預測為例,可以看出信諾在誤差值中的表現,從4.00%的誤差降到1.15%,表現的確更為優良。
在信諾系統的支持下,每年預測誤差最低可縮小至0.28%,而額外擷取的數據誤差亦僅1.85%,在每季約3億的徵收費用中,誤差僅約600萬,顯著優於傳統方法。此外,在平均絕對百分比誤差(MAPE, Mean absolute percentage error)方面,信諾能將誤差控制在2%以下,相較之下,傳統方法則多在2%以上。
信諾透過多模型協作進行數據運算,單一模型包括線性回歸、決策回歸樹、支援向量機和人工神經網路,以及複合模型(如表決法和重複採樣平均表決法)。根據數據樣態的特性進行最合適的模型搭配,再通過敏感度測試的精細運算,優化並篩選出最佳模型。為避免過度擬合問題,信諾採用交叉驗證法對模型進行公平評測,確保模型的穩定性與可靠性,進一步提升預測精度,提供案主更具信賴度的預測結果。
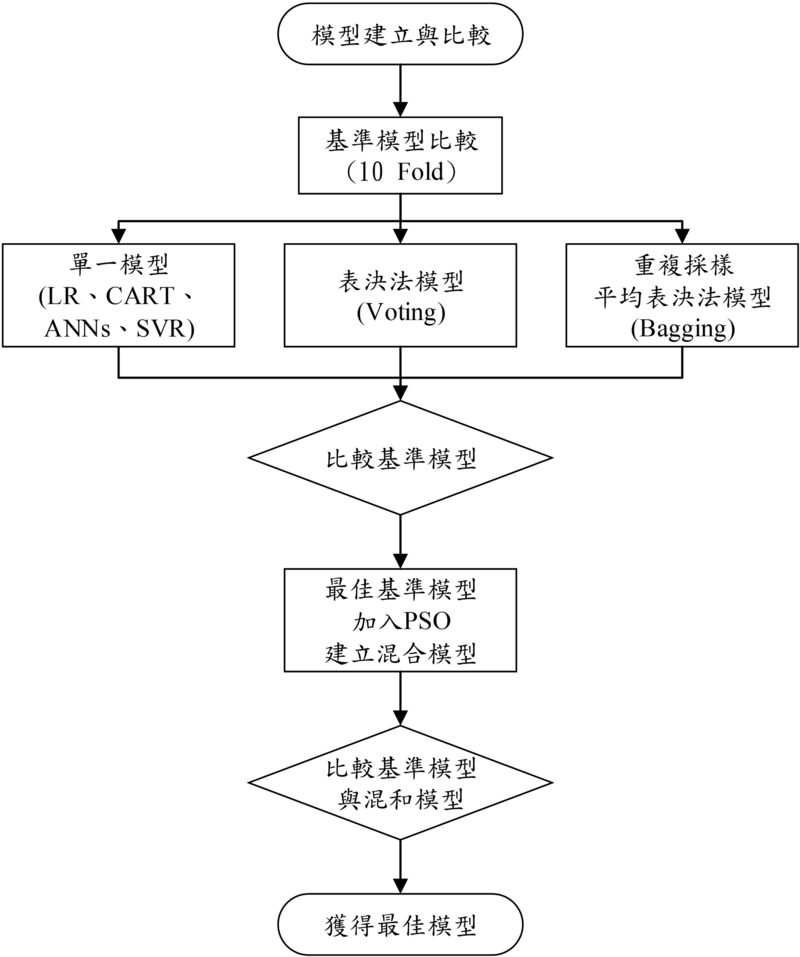 圖說:透過多種模型協作的方式,在繁複工法與嚴謹流程下建立的最佳模型能確保達到更準確的預測效能。
圖說:透過多種模型協作的方式,在繁複工法與嚴謹流程下建立的最佳模型能確保達到更準確的預測效能。
信諾目前的運算流程採用了臺科大PIM研究室(Project Intelligence & Management, PiM)的審核流程,確保數據處理的科學性和準確性。從獲取資料開始,信諾依序進行文獻回顧、資料觀察與處理、數據分析,並建立模型。為了確保模型的準確性與公正性,信諾在模型構建過程中使用了多種方法,包括交叉驗證法,藉此篩選出最合適的模型,使該組數據獲得更精準的預測效果。
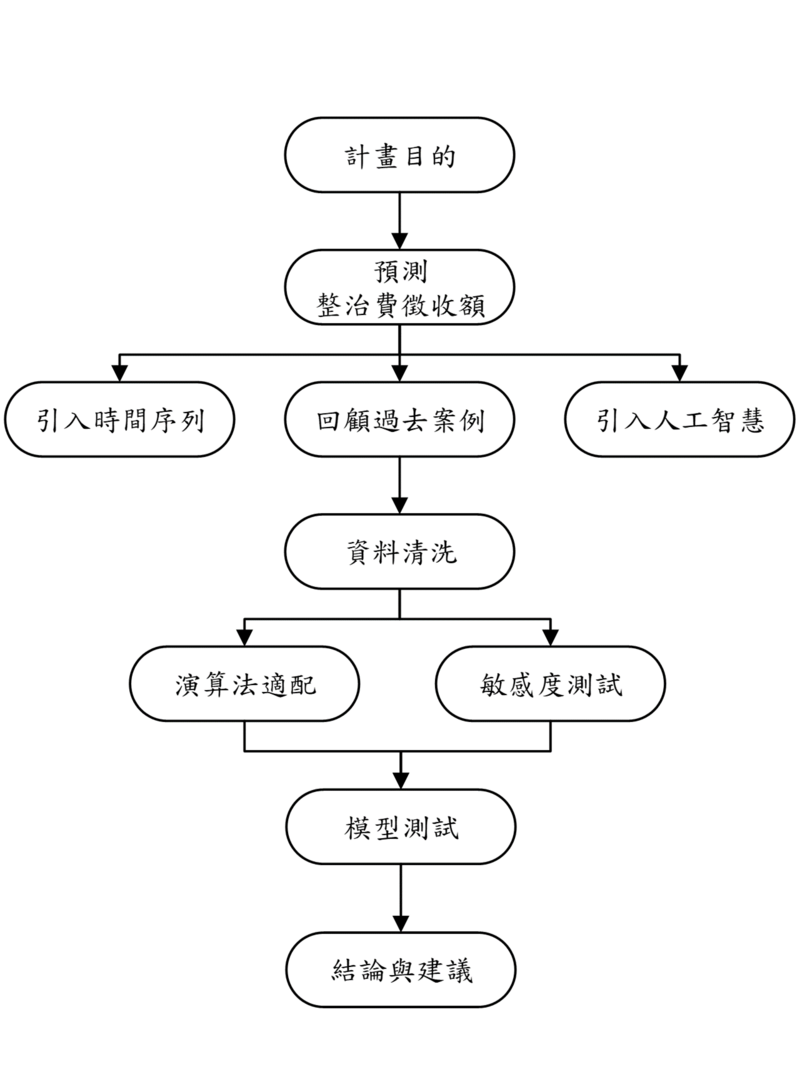 圖說:信諾在嚴謹的研究架構流程上保障了預測效能的精準度。
圖說:信諾在嚴謹的研究架構流程上保障了預測效能的精準度。
結語
信諾導入時間序列分析,並針對各類數據樣態提供精準匹配的演算模型。藉由臺科大PIM研究室的嚴謹作業流程,信諾進行多模型排列組合測試與繁複運算,並通過交叉驗證法全面評估模型的可靠性,確保方法上的高度嚴謹性,進而有效降低誤差值。此外,此系統能為案主提供多達六種預測模型選擇,使其具備更高的靈活性與精確度。
回上一頁